一、以RDD为基石的Spark编程模型
在Spark中一切都是基于RDD的:
什么是RDD呢?官方给出的解释是:

也就是说每个RDD都至少有以下三个函数实现:

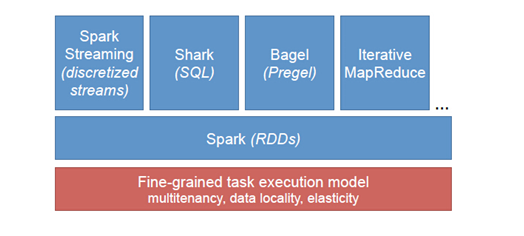
Spark自带了非常多的RDD:
RDD主要分为两种:

其中的transformations是lazy execution的,需要具体的action去触发,每个action操作都是一个单独的job;
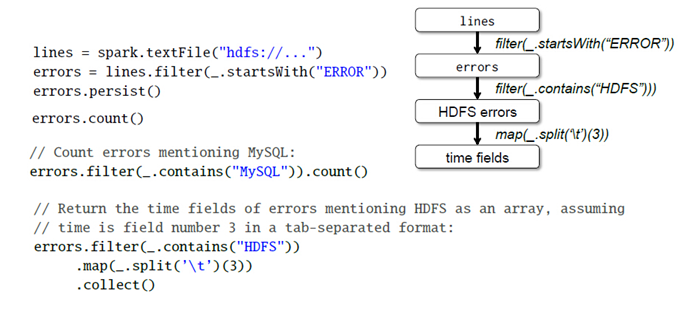
接下来我们看一个具体的RDD操作的例子:
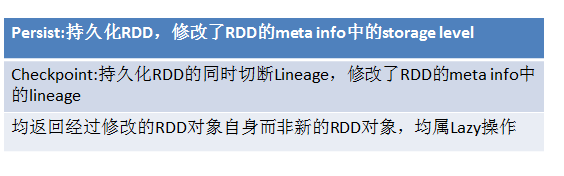
RDD中有两个比较特殊的RDD:

这两个RDD的特殊之处在于皆是控制性操作的RDD:
二,RDD的依赖和运行时
在Spark中RDD是具备依赖关系的,而依赖分为两种:

“Narrow”依赖的一个好处就是可以进行内部的pipeline操作:

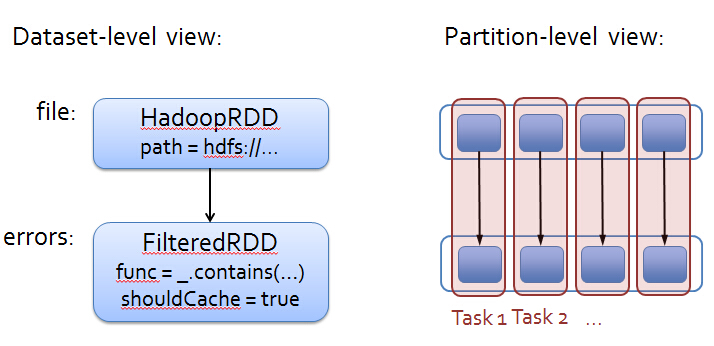
运行的时候是以RDD为统一抽象并行化运行:
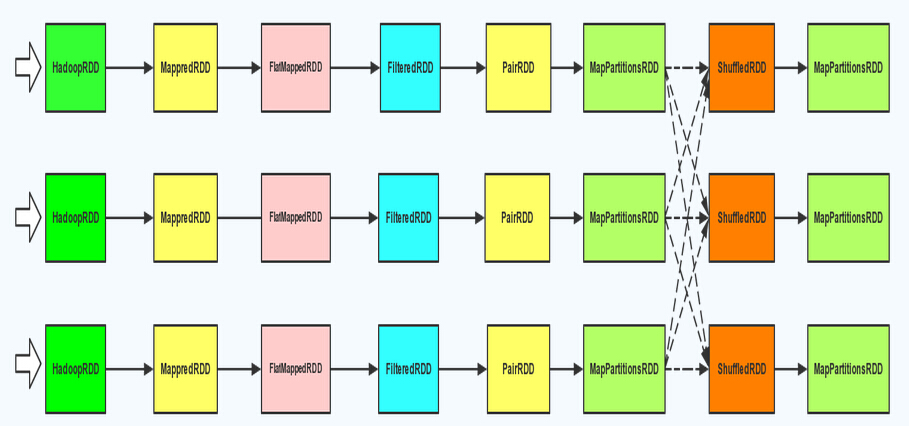
更进一步的详细RDD并行化计算过程如下所示:
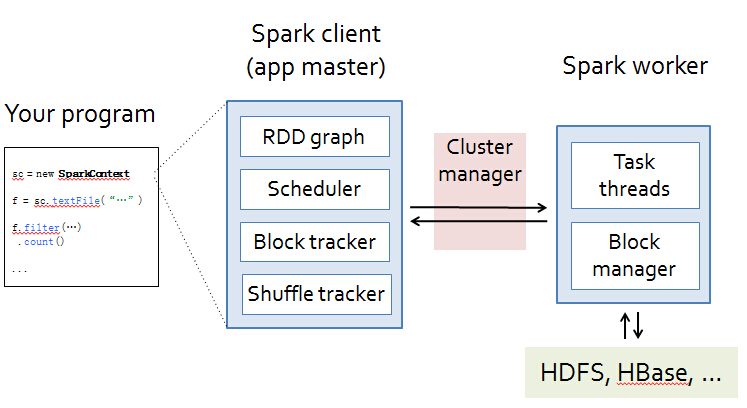
正如所有的分布式结构一样,Spark分布式集群也是主从结构的:

Spark运行时组件如下所示:
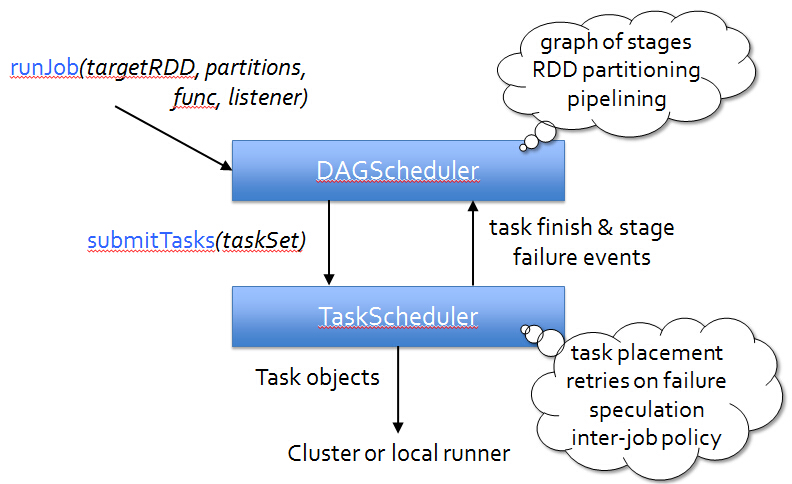
Spark运行时候的事件流如下所示: